如何用AI写业务代码
我们知道,用AI写通用代码是非常容易且准确的,例如很容易让AI写一个冒泡排序或者时间格式处理工具函数,因为AI大模型训练的素材就来源于互联网上的通用知识和算法。但是,AI并没有通过我们的业务代码进行训练,所以按道理来讲,AI是写不出我们的业务代码的。那我们如何让AI变得也会写我们的业务代码呢,本文就是想解决这个问题。
如何让AI理解业务
要让AI写出业务代码,那就等价于需要让AI理解业务,就目前主流的方式,有以下四种:
function calling 函数调用
MCP 模型上下文协议(今天的主题)
RAG 检索增强生成
Fine-tuning 微调
什么是MCP
MCP全称是Model Context Protocol,翻译为模型上下文协议。MCP是一种以json格式的明文传输协议。
以一个城市温度查询服务的MCP为例,它的请求和返回格式例如下:
1 2 3 4 5 6 7 8 9 10 11 12 | |
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
MCP服务有两种启动形式,第一种是stdio,以本地rpc的方式和大模型进行通信;第二种是http server,与大模型可以本地或者远程通信。
MCP本质上是规定了一个统一标准协议,让大模型可以方便的调用外部工具。说到这里,让笔者想起来以前一个很火的概念SOA(Service-Oriented Architecture),这么多年兜兜转转还是这些思路。
大模型与MCP的结合应用
有了MCP能力,我们就可以将业务里的工具以MCP的方式进行封装,供大模型使用。例如我们可以让大模型去调用我们的生成代码服务,并将生成的代码返回给大模型。这时候大模型拿到的代码就不是一个通用知识代码,而是一个符合我们业务领域知识的代码。由于MCP工具是确定性的,所以通过这种方式,我们可以减少大模型输出的幻觉问题,让大模型可以稳定高质量输出我们想要的业务代码。
例如,我们可以有以下一些MCP服务:
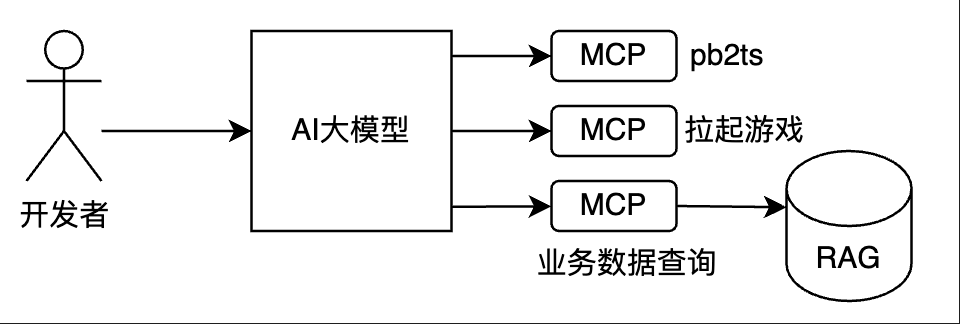
pb2ts:根据开发者输入的Protobuf协议文件,生成前端Typescript网络请求代码,并将相关代码自动上传到项目git仓库,更新本地仓库文件。开发者可以直接在IDE里使用最新的Typescript代码完成网络请求功能。
拉起游戏:比如我们的项目需要拉起一个外部游戏或者App,那么我们可以让MCP返回固定的业务代码,通过某个SDK来进行外部拉起
RAG:我们的MCP还可以连接RAG向量检索,进行相关的查询服务,将数据结果返回给大模型分析和使用
在这种情况下,AI大模型用作自然语言的语义理解和意图识别,然后判断调用哪些MCP服务来完成功能,这正是大模型的强项。而MCP的任务是按照标准协议提供项目特定的工具给大模型,使大模型的输出更加有确定性,减少大模型幻觉产生,并且能够理解我们的业务相关功能和代码。
pb2code MCP的功能和实现
笔者在项目里实现了一个pb2code服务,用户可以输入pb协议文件地址,生成业务特定的网络请求代码。具体的交互如下:
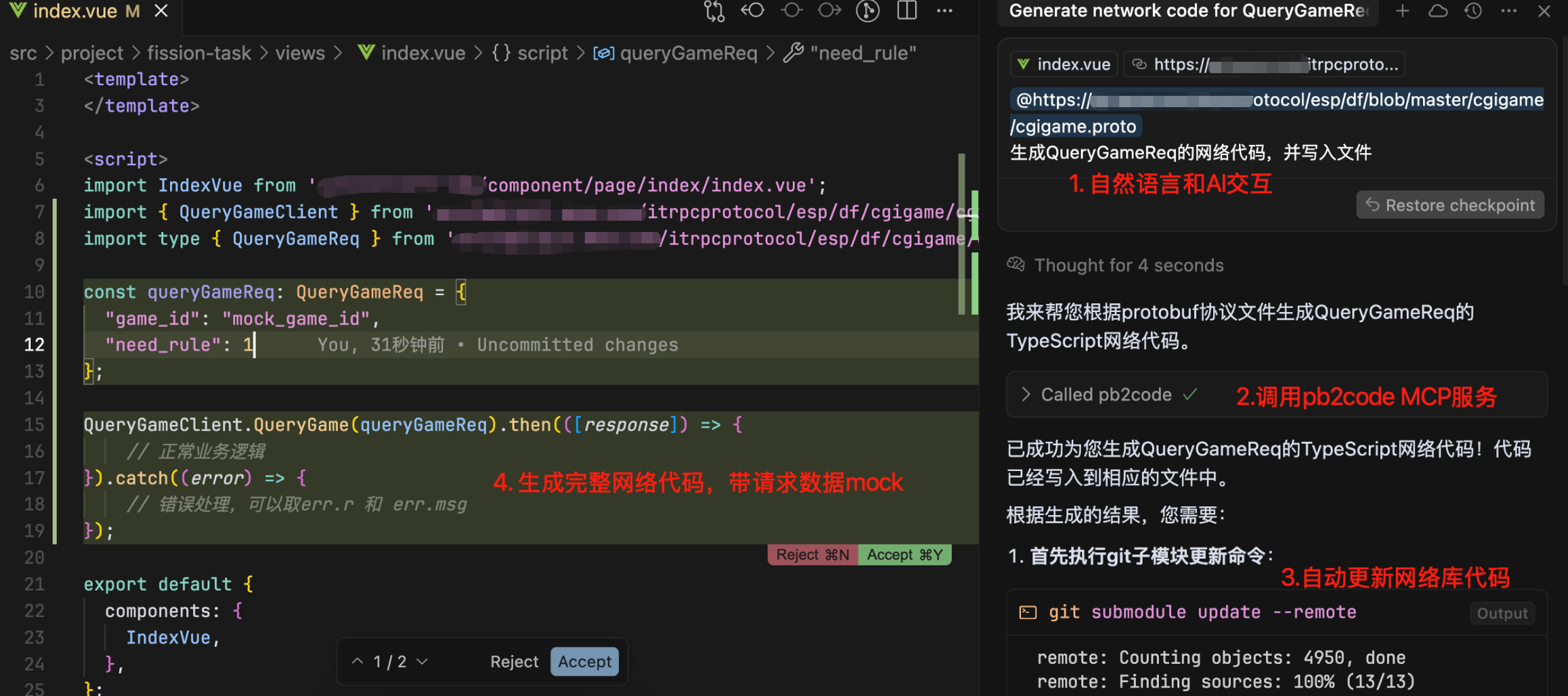
开发者只需要在AI聊天框里说:根据某个协议生成某个网络请求代码,就可以很方便完成相关代码的编写。MCP服务完成了以下事情:
拿到大模型解析出来的pb文件网络地址和请求名两个参数
调用项目内的研发平台服务,(1)生成ts代码(2)代码上传git(3)生成请求mock数据
输出命令
git submodule update --remote让大模型更新子仓库。子仓库里是第2步生成的网络请求ts代码,更新后本地可以引用输出业务代码,让大模型将业务代码写入代码编辑区
这段网络请求代码是基于我们项目的网络框架编写的,如果让大模型基于通用知识去写,是无法写出这样的特定业务逻辑代码的。
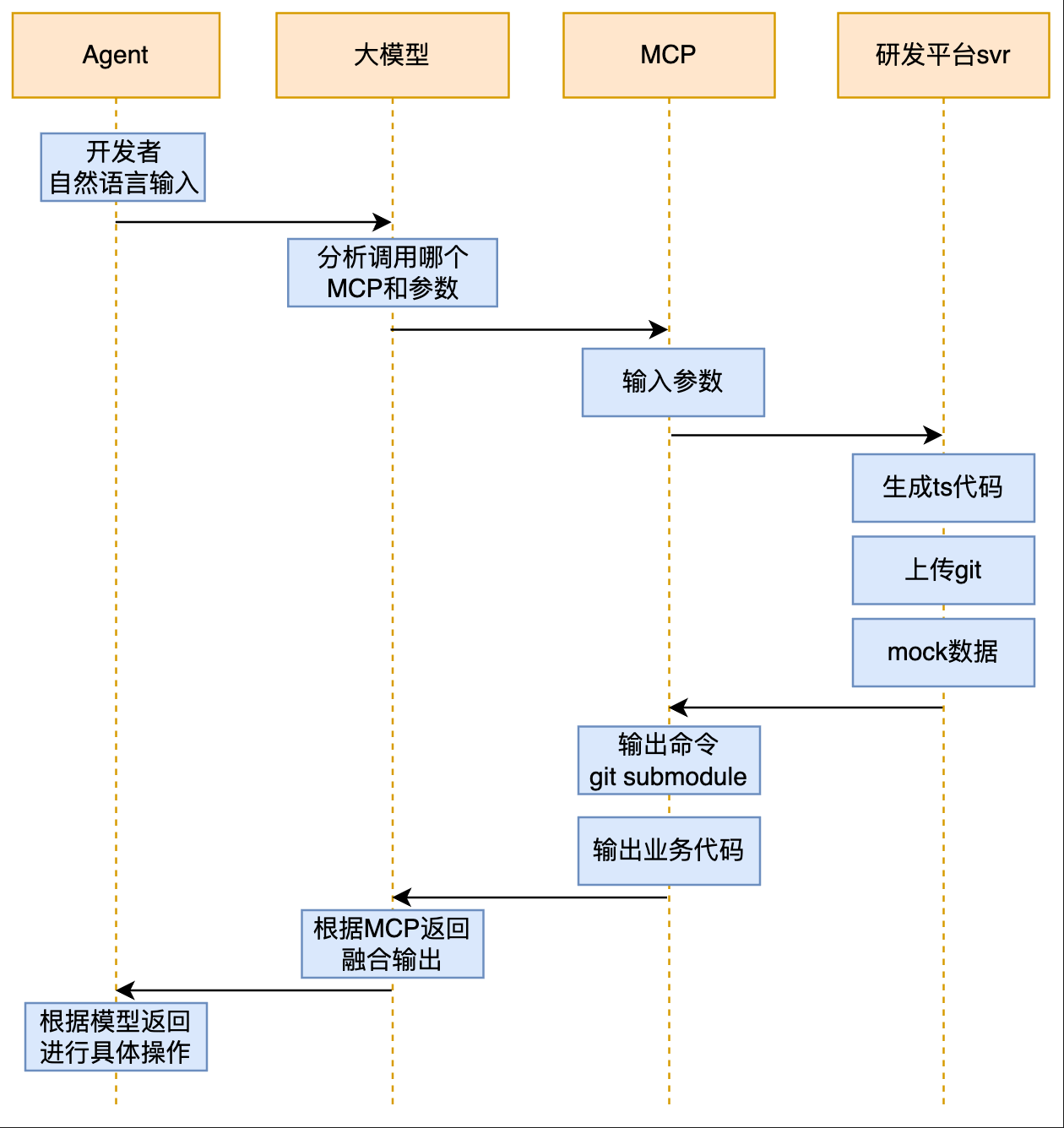
各模块整体交互流程如下图:
思考与展望
基于MCP,我们可以提供更多的模块服务,辅助AI来编写业务代码。除了调用外部工具之外,我们还可以借助RAG技术,进行业务代码的检索,然后通过MCP的方式提供接口给大模型调用,后面可能会在这方面做一些尝试。